Git Commands You Probably Do Not Need
Contents
Ah, git! Love it, hate it. Few things are as central to the modern software
development workflow as source-control management (SCM) tools. Although there
have been and still are plenty of alternatives to git in the world of SCMs,
none other seem quite as prevalent both in open-source and the enterprise.
Regardless of how central git has grown to be for many (most?) software
developers, I frequently get the impression that people have a tendency to shy
away from anything beyond the relatively basic functionality it provides.
Since its very inception git has been notorious for its often unfriendly,
inconsistent and occasionally hostile command line interface:

The image above was generated using git-man-page-generator.lokaltog.net and does not depict a real git command.
In this post I’ll present a few git commands and operations I run or have run
on occasion, in no particular order, that the majority of git users out there
might not ever need.
The empty commit ∅
git is designed to track content and changes to that content over time, so
creating empty commits doesn’t sound like a very productive or sensible thing
to do. Not adding any content might seem like a waste.
Yet, I know off the top of my mind at least two occasions where creating an empty commit can make quite a bit of sense:
- Initializing new repositories.
- Triggering continuous deployment pipelines.
1. Initializing a new repository
My main reason for using the --allow-empty flag to git is to create an
initial commit in a repository before I have any content for it.
Why?
Primary reason for me is that git rebase is somewhat troublesome when wanting
to rewrite the first commit of a repository. The rebase command centers around
working against an <upstream> commit1, and by definition the first commit
of a branch has no upstream. In later versions of git the --root option has
been added to remedy this, but I still like to use the opportunity to start any
new line of history with an empty commit:
❯ git commit --allow-empty -m "Initial commit"
❯ git show --stat 592f9dd06d1013e4b5300311e6c1b7033c17ab9b
commit 592f9dd06d1013e4b5300311e6c1b7033c17ab9b
Author: Martin Øinæs Myrseth <myrseth@gmail.com>
Date: Thu Dec 21 21:25:24 2017 +0100
Initial commit
Observe that the typical diff of the git show command is missing. There was
no content in this commit.
2. Trigger a build
Depending on your continuous integration/deployment setup chances are that
automated work is scheduled based on updates to some git repository. Alas,
flaky network and computation resources, tests and dependency management often
come in the way of a flawless pipeline execution.
Creating empty git commits and pushing them to a PR might be all you need to
scratch that “let’s just try it once more, without changing anything” itch.
Pushing locally 💨
It’s hard to use git for long without encountering git push, the git
sub-command for transferring (copying) stuff from your local repository to some
other, remote git repository. The format of the command I’m sure most people
are familiar with is:
git push <remote>
Or for the more adventurous:
git push <remote> <refspec>
Now what if I told you it’s possible to push a remote reference to your local repository, effectively reversing the direction of the push operation?
git push . origin/main:main
The dot (.) in the command above is what tells git that the destination
repository is the current directory. It’s equivalent to ./ or the absolute
path of the repository (i.e. $(pwd)).
Why on earth would you ever want to do this? Haven’t you heard of git pull?
Well, first off git pull is a combination of two git operations: git
fetch followed by either a git merge or a git rebase depending on user
configuration. In other words, a fetch followed by an integration2.
Since the integration can result in conflicts, git will only allow you to integrate into the current branch. After all, conflicts must be resolved in the worktree, and the worktree sees only the current branch (by definition). This is not always desirable.
Remote-tracking branches are git references (refs) typically stored in
.git/refs/remotes/<remote-name>/<branch-name> which keep track of the branch
state of a remote repository. For the most part the remote-name and branch
combinations are unambiguous allowing references to remote-tracking branches to
be abbreviated like origin/main. These references are managed by the git
fetch command primarily. It’s important to be aware that git does not hit
the network to check for updates when simply referring to refs like
origin/main.
Let’s say that you have been working for a long-ish period of time on a feature
branch, leaving your local copy of the project’s main branch significantly out
of date. For whatever reason (diffing, cherry-picking, etc) you want to update
main with the latest upstream changes, but you don’t want to navigate off
your feature branch3. One reason might be to avoid invalidating much of a
slow-running incremental build.
In this case we specifically do not want the integration phase of a git
merge or git rebase, rather we just to update a branch without having to
check it out first4. As it happens, this exactly what git push does:
When git push pushes to a remote repository, there is no opportunity to
resolve conflicts, instead the update either works (fast-forward, or maybe
you’re using --force) or it is rejected: there is no integration phase.
We just need to turn the direction around: Instead of pushing a local branch
into the remote repo, we want to push a remote branch into the local repo.
The dot (.) target takes care of the local repo part, but we need to cheat a
little to get the remote branch. As already mentioned, git fetch will
fetch remote branches into the local repo, and update the corresponding
remote-tracking branches in your local repo[remote-tracking-branches]. From
there, you can now use the remote-tracking branch as the source of your `git
push`:
# update remote-tracking branches (incl. origin/main)
git fetch
# Update main branch in this repo to point the same place as origin/main
git push . origin/main:main
git provides the same branch protection rules as when pushing to remote
repositories. Which is to say that it denies non-fast-forward pushes by default,
but allows overrides through +<commit>:<ref> refspecs, or the --force and
--force-with-lease command line options.
Keep in mind that using these overrides are destructive and may lead to
dataloss. Always create a backup branch with something like git branch
<some-temp-name> <branch-to-update> if you’re not 100% certain you’re in
control of what’s going to get pushed.
Commit ranking 🥇
Perhaps in need for something to serve as the year-end bonus rounds tie-breaker? What better way to settle the implicit battle between your peers of “who’s providing most value” than by having a “git commit count” showdown?
No, that’s a horrible idea …
Yes, yes it is. Any sensible developer knows that nothing good ever comes out of placing merit in lines of code changed or number of commits committed.
But should you, God forbid, ever be in need to know (for the sake of
curiosity) who’s been committing the most to a repository, here’s git rank:
git shortlog -s -n --no-merges
Configure it as an alias in ~/.config/git/config with:
[alias]
rank = "shortlog -s -n --no-merges"
and simply run:
git rank
As a quick example, behold, here’s the horrendous output from my own dotfiles
repository, where I’ve been able to make commits under different names and
identities:
❯ git shortlog -nse
567 Martin Øinæs Myrseth <myrseth@gmail.com>
322 Martin Øinæs Myrseth <mmyrseth@cisco.com>
142 Martin Myrseth <mm@myme.no>
14 Martin Myrseth <myrseth@gmail.com>
4 Martin Øinæs Myrseth <mm@myme.no>
3 Martin Myrseth <myme@map>
2 Martin Øinæs Myrseth <myme@Tuple.localdomain>
2 Martin Øinæs Myrseth <myme@map.localdomain>
It’s painful to read, I know. Try to imagine the pain and embarrassment it is for me to share it. And have you been unfortunate or careless enough to get yourself into a similar situation, please read on. I’ll revisit this problem in the filter branch section below.
Cat file 🐈
This is more of a git party trick than anything to actually make much use of.
But I should say I have made use of git cat-file -p on a couple of occasions
to help people visualize and actually grok git’s data model.
As the name hints at, the cat-file command outputs information about git
objects. I’ve personally only used cat-file with the -p (pretty-print) flag,
which first determines the type of the object before printing it out. Let’s
start off with inspecting the HEAD commit:
$ git cat-file -p HEAD
tree 9491ada70010d722646b674d2e2a26521628df94
parent 9d7e5a6490c9f560f54fee9e1af5d72429bb26c7
author Martin Myrseth <mm@myme.no> 1665439490 +0200
committer Martin Myrseth <mm@myme.no> 1665439490 +0200
Delete Docker deploy action
We see the main metadata that git associates with a commit: the repository file
structure (tree), a parent commit SHA1 reference, author information and
finally the commit message after a blank line. Let’s dig further by passing the
SHA1 (9491ad..94) of the tree associated with the HEAD commit:
$ git cat-file -p 9491ada70010d722646b674d2e2a26521628df94
040000 tree 6d71faa5d70085c5d07228d8fa522fb712253b6d .github
100644 blob e09fe0dc282fdcaff06bcc6a9bbf57cbfc845eb4 .gitignore
100644 blob da7e7945524871726071f919690c9c9f6c1e173d README.md
100644 blob e6be557357c3fe2e3cce6f1b7b9b3c9c55981a16 default.nix
040000 tree 4f69a79c432cde80b4a1c486974b03cab84b45b9 docker
100644 blob 2f8aacd9efa3cfdf9e5f2860fa7226b510ed83bc feed-cors.conf
100644 blob 14b9e2dd0a41aa932c1f4bb5938519547f37f82c flake.lock
100644 blob eeae336837db94ca62255a7e5fa7f32ae3363716 flake.nix
100644 blob f1f8ef836b3b9b9ea011a43972a28ffaa713c868 image.nix
040000 tree 5cad033d973f19ece938c33c3bb912eb63dc3305 site
040000 tree 49dc35d8e519f02f6f1a647f437226af198d225a ssg
100644 blob 60dede4bba8cd9479b0bec49048da1397e14f352 todo.org
The result of printing a tree is what looks like a directory listing of the
contents of that “tree” directory. Each directory entry is represented as some
mode bits, an object type, the SHA1 of the object and the name of the entry.
Trees may contain other tree objects to create a directory structure, or
blob objects which contain file contents.
Finally, let’s inspect one of the blob in the output, like .gitignore
(e09fe0..b4):
$ git cat-file -p e09fe0dc282fdcaff06bcc6a9bbf57cbfc845eb4
.stack-work
_cache
public
dist-newstyle
.ghc.environment.*
# nix-build
result
Which prints out the actual content of .gitignore the way it was committed
into the current HEAD commit.
Wait? What? So everything is just text files?
Conceptually, yes. However, modern git does a lot more to optimize storage
(re)usage and whatnot to ensure that a repository stays as small as possible.
There are other, scarier objects lurking under .git/objects in a git
repository.
The git parable
As I said in the beginning of this section, I’ve used cat-file to help myself
and others understand the git object model. Learning all the details of that
model isn’t the purpose of this section (or post) though. However, if reading
this ignited some form of curiosity on your part I would gladly recommend the
talk “The Git Parable” which dives deeper into the git object model, as
presented by my good friend Johan Herland:
Use case
Now, why would you want to use cat-file? (Except you wouldn’t, but let’s just
play along here)
I was deep into some refactoring and clean-up of a set of template files used for various messages sent out from a system. Each template directory would contain a set of files for each message template. I’ve been working with the files for a while when a feeling grew on me that several of these templates seemed to be fairly similar, identical in fact.
At this point I had already been making some work-in-progress commits, which would definitely get in the way for any attempt at checking if there were identical template directories in my working copy. I wanted to compare the contents of the template directories at the point before I started making my changes.
The primary tool for checking differences to files in git is obviously the
git diff command. It can easily check the differences between files stored in
the git history. Typical usage of diff is to compare a single path across
various versions. However, looking closer at it’s synopsis we can see that there
are a couple of call signatures that might do somewhat what we need:
NAME
git-diff - Show changes between commits, commit and working tree, etc
SYNOPSIS
git diff [<options>] [<commit>] [--] [<path>...]
git diff [<options>] --cached [--merge-base] [<commit>] [--] [<path>...]
git diff [<options>] [--merge-base] <commit> [<commit>...] <commit> [--] [<path>...]
git diff [<options>] <commit>...<commit> [--] [<path>...]
git diff [<options>] <blob> <blob>
git diff [<options>] --no-index [--] <path> <path>
Primarily git diff <blob> <blob> which would let us compare any two git blob
objects. There’s also a note under “DESCRIPTION” which states:
Just in case you are doing something exotic, it should be noted that all of the
<commit>in the above description, except in the--merge-basecase and in the last two forms that use..notations, can be any<tree>.
Which means that also git diff <blob> <blob> should do something along the
lines that we want. And surely, doing something similar to the following yielded
an empty diff (where HEAD~3 is the commit I based my work on):
❯ git diff HEAD~3:some/templates/path/ HEAD~3:some/templates/other-path/
The manual page for git-diff states that it takes two blobs, but it’s just
as valid with any tree-like object, often called tree-ish in the git
documentation.
So I had found one pair of templates that were identical, and which could be
coalesced into one. But what if there were more? Using git diff alone I would
have had to compare all permutations of template directories to see if the
results were empty.
No time for that…
Instead we can use cat-file to simply dump all the hashes of every sub
<tree>. Then we can use a familiar shell pipeline to group the hashes and
count them:
❯ git cat-file -p HEAD~3:some/templates/ \
| awk '{ print $3; }' \
| sort \
| uniq -c \
| sort -rn
2 af83bb357f2b8dc42f6c9f07620140590dc7fd44
2 228182da5a0ffcf4c0d263bfa54852176f0250d2
1 ef1a471185c2092e6708349fa710702dd416f892
1 e453cb9d3dddbdd46a65c811068352ac40941fcd
1 e3df1181dae478172a7ae6bbc1618a3af2151db4
1 de0f6cd53ea97cb100a74c812f75c0d4844c0efa
1 d7f239da6283c927dad650599d49639ddc761465
1 d7d8f5aa3571ea2392028e353ad958d778d2bee0
1 cc03005d684b5735da337a6e5ca9765751943d7d
... # A bunch more
Et voilà! We clearly see that there are not just one pair of duplicate templates, but two!
I should note that this approach is brittle in the sense that should there be
any difference to the blobs at all this method falls apart. In my case it
worked perfectly, but your mileage might vary. In my experience there are often
several ways to do the “same thing” using git, so it would be nice to hear of
other approaches.
Orphan commits 🤷
Every commit in a git repository has a reference to its parent, which is the
commit that chronologically came immediately before the commit. For merge
commits the number of parents are greater than one.
Well, that’s not 100% accurate. As discussed in the empty commit the initial commit of a branch is somewhat special: it has no parents. Commits without any reference to a parent is called an “orphan” commit. In most repos there would only be one such commit, the initial commit.
However, git is by no means limited to a single orphan commit. The default
behavior when creating a new branch is that the new branch is based on some
start-point. Using git checkout --orphan (or the currently unstable git
switch --orphan) it’s possible to start off a completely new and independent
line of history totally disconnected from the rest of the repository.
The main use-case I’ve had for git’s support of this functionality is not to
start “orphaned” histories, but rather absorb the history of a branch from
another, unrelated repository. It’s very useful when coalescing many smaller
repositories into a monorepo or when vendorizing some library.
Merging histories
As a synthetic case-study let’s import the doomemacs history into my
dotfiles repo!
First let’s create a new worktree so that we don’t mess up my actual files:
❯ git worktree add ~/code/doomfiles doomfiles
Preparing worktree (checking out 'doomfiles')
HEAD is now at a0b32f8 machine: deque: Setup nginx with rtcp.myme.no
❯ cd ~/code/doomfiles
Doing a git log of the most recent commits we can see that they’re all mine:
❯ git log --oneline --graph -5
* 0f1f6cd machine: map: Enable podman
* 46099b9 emacs: Add React fn-component snippet
* 2e75458 ssh: Update hosts
* 445ade4 machine: deque: Set SSH port
* bf0a552 flake: Add utils as "apps"
Another “little known” feature of git is that it’s trivial to fetch “a random”
upstream repository without adding an explicit git remote. This can be quite
useful when e.g. checking out some incoming one-off contribution. Just pass the
remote url to fetch directly:
❯ git fetch git@github.com:doomemacs/doomemacs
remote: Enumerating objects: 118606, done.
remote: Counting objects: 100% (20/20), done.
remote: Compressing objects: 100% (17/17), done.
remote: Total 118606 (delta 4), reused 15 (delta 3), pack-reused 118586
Receiving objects: 100% (118606/118606), 26.98 MiB | 6.80 MiB/s, done.
Resolving deltas: 100% (82950/82950), done.
From github.com:doomemacs/doomemacs
* branch HEAD -> FETCH_HEAD
As the output states, the result of the fetch is placed in the special git ref
FETCH_HEAD. We can use this ref to refer to the doomemacs commit that was
fetched when we wish to merge the histories.
Now, git won’t let us merge without warning us first:
❯ git merge FETCH_HEAD
fatal: refusing to merge unrelated histories
Easily enough we can add the --allow-unrelated-histories telling git we’re
being quite serious right here:
❯ git merge --allow-unrelated-histories FETCH_HEAD
Auto-merging .gitignore
CONFLICT (add/add): Merge conflict in .gitignore
Auto-merging README.md
CONFLICT (add/add): Merge conflict in README.md
Recorded preimage for '.gitignore'
Recorded preimage for 'README.md'
Automatic merge failed; fix conflicts and then commit the result.
Pfffft, conflicts … Let’s get on with our lives by simply resetting the conflicting files to the imported versions #yolo.
❯ git checkout --theirs -- .gitignore README.md
❯ git add .gitignore README.md
❯ git commit -m 'Pulling in Doom Emacs!'
Recorded resolution for '.gitignore'.
Recorded resolution for 'README.md'.
[doomfiles 11826ae12] Pulling in Doom Emacs!
And that’s about it! Let’s inspect the result:
❯ git show
commit 11826ae125834cc4e2263172275d8c51bca11d63 (HEAD -> doomfiles)
Merge: a0b32f85f e96624926
Author: Martin Myrseth <mm@myme.no>
Date: Thu Jan 19 01:13:17 2023 +0100
Pulling in Doom Emacs!
We can see that the commit is a merge commit, where one parent is a0b32f85f from
my dotfiles while the other parent e96624926 is the current5 HEAD from the
doomemacs repo.
We have successfully merged the histories of my dotfiles repository with Doom
Emacs!
As stated previously, this can be quite useful when pulling in e.g. an experimental repository, vendorizing some dependency or similarly constructing a monorepo from separate smaller repositories.
The next section is about one (of several) times I’ve found this useful myself.
Dotfiles bankruptcy
I agree that the previous example of absorbing Doom Emacs into my dotfiles is kind of silly, but it illustrates possibilities.
Stepping away from synthetic examples I also would like to show one of a few occasions where I’ve made use of it to solve a real-world use-case.
Let’s step back into my dotfiles.
With our new knowledge about orphan commits we may wonder if there is a way to easily query for them in a git repository. And there sure is:
❯ git log --all --max-parents=0
commit 6fa853118711f557a911b98f00d5c4a2eb3ded71
Author: Martin Myrseth <mm@myme.no>
Date: Mon Jan 17 21:44:43 2022 +0000
nixos: Initial commit
commit 61a3f80babec8c1339391462590dafe7ff30fe7f
Author: Martin Myrseth <mm@myme.no>
Date: Wed Feb 10 11:59:23 2016 +0100
Inital import of tuple
There is not one, but two commits in the dotfiles repository which doesn’t
have any parents.
- The real “Initial import” created at the beginning of time6.
- The much more recent “nixos: Initial commit”.
The second commit was the beginning of my attempt to move my machine
configurations towards a fully NixOS managed declarative setup built on top of
flakes. I’ve already covered this journey in another post which also links to
the state of my configuration management before that migration.
In any case, when starting my configuration rewrite I wasn’t yet sure if I would
want a clean slate or eventually port it into my dotfiles. In the end I
figured I could have both, by simply pulling in the experiment into my already
existing history.
Eventually my experiment had matured to the point where I was convinced I had
what I wanted. It was time to import it into the dotfiles repository.
Following pretty much the same steps as in the previous section I ended up with
the following merge commit:
❯ git show 79977b007099390a53e11f540e178f6285137206
commit 79977b007099390a53e11f540e178f6285137206
Merge: ad28da4 841eec3
Author: Martin Myrseth <mm@myme.no>
Date: Wed Feb 2 00:19:24 2022 +0100
nixos: Declare dotfile bankruptcy
I remember reading an email thread on the git mailing list in the early days
of git where Linus Torvalds boasted performing this “absorption” operation in
order to pull in some unrelated history.
And equally interesting I remember reading an analysis which touched on how many
orphan commits there are in the Linux main tree. I remember there being four,
one in particular seemed like a “careless” unintentional mistake.
Edit 2023-01-23:
Initially I didn’t spend enough effort trying to find these two sources, but both through help from readers and some more search-fu vigilance I was able to find what I was referring to:
From lore.kernel.org: Behold, The coolest merge EVER!
Thanks to a reader I was directed towards exactly the post I was after that researched “weird”
Linuxcommits (from Destroy All Software):“The Biggest and Weirdest Commits in Linux Kernel Git History” goes through both octopus merges and orphaned commits in the history
Linux.
Filter branch 🌿
The git filter-branch command has got WARNING written all over it. Please
proceed with caution. This section illuminates usage of filter-branch to fix a
particular problem. As the section goes on to explain, there are better, less
destructive ways to resolve these problems.
I tend to work in a number of git repositories across various machines. I also
split work between my personal projects and anything related to $DAYJOB. I do
not want to taint the git history in work repositories with personal email
addresses and other “unprofessionalism”.
Turns out I do though. Remember the painful output from commit ranking?

Oh, the embarrassment! It’s unbearable!
This example is was from my dotfiles history before I cleaned it up. I
occasionally setup new machines, and my dotfiles repo is the first thing I
pull in after the machine boots. Every host typically needs some form of
tweaking, and not realizing I haven’t setup my git configurations correctly, I
start patching and committing configurations for the new host.
Next thing I know I’ve completely missed the fact that I’ve been committing with
all kinds of ad-hoc user settings inferred from git without letting me know.
I’ve been aware of this potential issue for a long time, and have proactively
tried to mitigate it using various strategies on several occasions in the past.
Sometimes bad commits manage to slip through though. With a stricter focus on a
holistic nix flakes host setup, I hope I’m rid this issue of partial
(mis)configuration once and for all.
The filter-branch cleanup
Most people familiar with rewriting git history know about git rebase and
git rebase --interactive, which allow operations like “moving” (or replaying)
commits onto new parents, rewriting commit messages, re-assigning author
information, as well as making changes to the source tree.
Perhaps less familiar to people is the git filter-branch command, which is
sort of the hydrogen bomb of history rewriting. I urge you to heed the glaring warning
that meets you in man git-filter-branch(1) and perhaps consider alternative
solutions like git-filter-repo:
WARNING
git filter-branch has a plethora of pitfalls that can produce non-obvious
manglings of the intended history rewrite (and can leave you with little
time to investigate such problems since it has such abysmal performance).
These safety and performance issues cannot be backward compatibly fixed
and as such, its use is not recommended. Please use an alternative
history filtering tool such as git filter-repo. If you still need to use
git filter-branch, please carefully read the section called “SAFETY” (and
the section called “PERFORMANCE”) to learn about the land mines of
filter-branch, and then vigilantly avoid as many of the hazards listed
there as reasonably possible.
Warning aside, a few factors lead me to believe this was what I wanted in this particular scenario:
- All the faulty commits were fairly recent, I wouldn’t touch very old history.
- I’ve had experience running
filter-branchfrom way back and felt confident choosing it again. - The manpage has the exact use-case exemplified.
With a few modifications from this Stack Overflow answer:
❯ git filter-branch --env-filter '
WRONG_EMAIL="martin@machine.localdomain"
NEW_NAME="Martin Myrseth"
NEW_EMAIL="martin@example.com"
if [ "$GIT_COMMITTER_EMAIL" = "$WRONG_EMAIL" ]
then
export GIT_COMMITTER_NAME="$NEW_NAME"
export GIT_COMMITTER_EMAIL="$NEW_EMAIL"
fi
if [ "$GIT_AUTHOR_EMAIL" = "$WRONG_EMAIL" ]
then
export GIT_AUTHOR_NAME="$NEW_NAME"
export GIT_AUTHOR_EMAIL="$NEW_EMAIL"
fi
' --tag-name-filter cat -- --branches --tags
I do not have the output of this command ready at hand. It’s a while since I ran it, and I do not intending to do it again any time soon. All I can say is it worked out nicely for me.
I don’t think there’s much reason to invest a whole lot of effort into
understanding all the ins and outs of filter-branch. There are most likely
always better options to solve the problems it too can solve, so try your best
to avoid it.
Following are some other workarounds to avoid committing with a broken user
configuration or ensuring that faults are at least concealed in command outputs.
Git templates and pre-commit hooks
Before all of the other mitigations outlined in the sections below I used to
have a .gittemplates folder containing a few git hooks that would be added
to every newly created repository. One of these hooks was the pre-commit hook
which checked that I had a properly configured user.name and user.email.
#!/usr/bin/env bash
if !(git config user.name &> /dev/null && git config user.email &> /dev/null); then
echo "Please setup your repository with a user.name and user.email" >&2
exit 1
fiIf I ever forgot to properly setup particularly the user.email for a specific
repository then git wouldn’t let me commit without annoying me with a warning.
Since I rarely change my name (I haven’t yet), I would hardcode user.name into
my user-global git configuration.
Due to the chicken-and-egg problem, these hooks weren’t created for my
dotfiles repo on new hosts because they’re in the dotfiles repo. It’s a
while since I abandoned this approach alltogether as it’s obsoleted by the
solution of the next section.
Keep in mind this was added a while ago, and before I’d learned about the superior means of working around this problem which I’ll get to below. This solution is most likely not what you want.
No second guessing please!
One of the git defaults I’m not very fond of is the user.useConfigOnly
configuration which is false by default. Here’s its excerpt from man
git-config(1):
user.useConfigOnly
Instruct Git to avoid trying to guess defaults for user.email and user.name,
and instead retrieve the values only from the configuration. For example, if
you have multiple email addresses and would like to use a different one for
each repository, then with this configuration option set to true in the
global config along with a name, Git will prompt you to set up an email
before making new commits in a newly cloned repository. Defaults to false.
I guess the documentation outlines my “default” use-case, which is to use
different email addresses for the repository I work in. With the following
configuration git will refuse to commit when user configuration is missing,
thus obsoleting my pre-commit hook:
[user]
name = "Martin Myrseth"
useConfigOnly = true
Git conditional configuration
It’s hard to argue against the fact that the best way to solve any problem,
is to not have the problem in the first place. Using some “clever” conditional
configuration sections it’s possible to include additional configurations for
e.g. repositories within specific sub-directories on the filesystem, ensuring
that there never is a partial user configuration.
Once I became aware of this configuration trick I took more care as to where I
placed repositories on disk. Making sure to have separate directories for
personal and work related repos. With this repository directory layout, it’s
possible to have a conditional section in gitconfig which applies additional
configurations to any repository matching the predicate (i.e. placement on
disk):
[includeIf "gitdir:~/code/work/"]
path = "./work_config"
Any repository under ~/code/work will include the configuration from
./work_config, which may contain something like the following:
[commit]
gpgSign = true
[tag]
forceAnnotated = true
gpgSign = true
[user]
email = "martin@day.job"
signingKey = "martin@day.job"
.mailmap
Although the filter-branch command allows a full cleanup of the history of a
git repository, it shouldn’t be understated the potential damage and
inconvenience such an operation has on the repository integrity. Rewriting
history has the viral effect of changing SHA1 sums of all subsequent commits,
leading to parallel histories (old vs. new). This is most likely not what you
want for public histories.
On the other end of the spectrum git provides a rather convenient and
non-destructive feature to solve this particular issue through its mailmap
support. Quoting the man gitmailmap:
If the file
.mailmapexists at the toplevel of the repository … it is used to map author and committer names and email addresses to canonical real names and email addresses.
The man page of gitmailmap contains syntactical examples of mailmap entries.
To correct a simple incorrect email one can add an entry on the format:
<proper@email.xx> <commit@email.xx>
The .mailmap can also correct user.name issues as well as correct specific
commits and so on. Here’s the .mailmap file from my dotfiles which fixes up a
few of my past mistakes:
Martin Myrseth <mm@myme.no> <mm@myme.no>
Martin Myrseth <mm@myme.no> <myrseth@gmail.com>
Martin Myrseth <mm@myme.no> <mmyrseth@cisco.com>
Martin Myrseth <mm@myme.no> <myme@Tuple.localdomain>
Martin Myrseth <mm@myme.no> <myme@map.localdomain>
Octopus merge 🐙
I must admit, I never use this, but I remember being amazed the first time I learned about the many-parent merge ability of git long ago.
I would assume most people live their life thinking a merge commit is just the combined result of two somewhat related histories. Ideally two histories that forked off one another in (hopefully) the not too distant past.
Yet, we’ve already seen and debunked the fact that histories have to be “somewhat related” in order to be merged. That’s what the “absorb some other repository” functionality covered in the orphan commits section was all about.
I guess then it comes as no surprise that the assumption of merges only ever having just two parents is also not a hard limitation.
Tentacles
Let’s see how we can create a many-parent merge commit, called an “octopus merge”, by starting off a new repository and adding a bunch of branches to it:
❯ mkdir octopus
❯ cd octopus/
❯ git init
Initialized empty Git repository in /home/myme/tmp/octopus/.git/
❯ git commit --allow-empty -m 'Initial commit'
Author identity unknown
*** Please tell me who you are.
Run
git config --global user.email "you@example.com"
...
Ah … right. Forgot about that 🤦
❯ git config user.email 'dave@tentacle.org'
❯ git commit --allow-empty -m 'Initial commit'
[main (root-commit) 9ff0a71] Initial commit
At this point we have a new git repository with a single main branch containing a single empty commit:
❯ git log --all --oneline --graph
* 9ff0a71 (HEAD -> main) Initial commit
Let’s create some branches with content:
❯ git checkout -b tentacle
Switched to a new branch 'tentacle'
❯ date > tentacle.txt
❯ git add tentacle.txt
❯ git commit -m 'Add day of tentacle.txt'
[tentacle 4dadc16] Add day of tentacle.txt
1 file changed, 1 insertion(+)
create mode 100644 tentacle.txt
Yay, one limb (aka branch) in place!
❯ git log --all --oneline --graph
* 4dadc16 (HEAD -> tentacle) Add day of tentacle.txt
* 9ff0a71 (main) Initial commit
But creating limbs is tedious. Let’s push the fast-forward button:
for count in nine eight seven six five four three two one; do
limb="${count}tacle"
git checkout -b "$limb" main
date > "${limb}.txt"
git add "${limb}.txt"
git commit -m "Add ${limb}"
doneSwitched to a new branch 'ninetacle'
[ninetacle 3f7a95e] Add ninetacle
1 file changed, 1 insertion(+)
create mode 100644 ninetacle.txt
Switched to a new branch 'eighttacle'
[eighttacle e9cd39a] Add eighttacle
1 file changed, 1 insertion(+)
create mode 100644 eighttacle.txt
Switched to a new branch 'seventacle'
...
Switched to a new branch 'sixtacle'
...
Switched to a new branch 'fivetacle'
...
Switched to a new branch 'fourtacle'
...
Switched to a new branch 'threetacle'
...
Switched to a new branch 'twotacle'
...
Switched to a new branch 'onetacle'
[onetacle c78c58a] Add onetacle
1 file changed, 1 insertion(+)
create mode 100644 onetacle.txt
And we got ourselves a bunch of limbs!
❯ git log --all --oneline --graph
* e9cd39a (eighttacle) Add eighttacle
| * e310cbc (fivetacle) Add fivetacle
|/
| * 44ad755 (fourtacle) Add fourtacle
|/
| * 3f7a95e (ninetacle) Add ninetacle
|/
| * c78c58a (HEAD -> onetacle) Add onetacle
|/
| * 6be7cf4 (seventacle) Add seventacle
|/
| * a54e5c1 (sixtacle) Add sixtacle
|/
| * 3b1a5da (threetacle) Add threetacle
|/
| * bb79112 (twotacle) Add twotacle
|/
| * 4dadc16 (tentacle) Add day of tentacle.txt
|/
* 9ff0a71 (main) Initial commit
Time to assemble our squid:
❯ git merge tentacle ninetacle eighttacle seventacle sixtacle fivetacle fourtacle threetacle twotacle onetacle -m 'Assemble squid'
Fast-forwarding to: tentacle
Trying simple merge with ninetacle
Trying simple merge with eighttacle
Trying simple merge with seventacle
Trying simple merge with sixtacle
Trying simple merge with fivetacle
Trying simple merge with fourtacle
Trying simple merge with threetacle
Trying simple merge with twotacle
Trying simple merge with onetacle
Merge made by the 'octopus' strategy.
eighttacle.txt | 1 +
fivetacle.txt | 1 +
fourtacle.txt | 1 +
ninetacle.txt | 1 +
onetacle.txt | 1 +
seventacle.txt | 1 +
sixtacle.txt | 1 +
tentacle.txt | 1 +
threetacle.txt | 1 +
twotacle.txt | 1 +
10 files changed, 10 insertions(+)
create mode 100644 eighttacle.txt
create mode 100644 fivetacle.txt
create mode 100644 fourtacle.txt
create mode 100644 ninetacle.txt
create mode 100644 onetacle.txt
create mode 100644 seventacle.txt
create mode 100644 sixtacle.txt
create mode 100644 tentacle.txt
create mode 100644 threetacle.txt
create mode 100644 twotacle.txt
The end result is the most wonderful git graph ever!
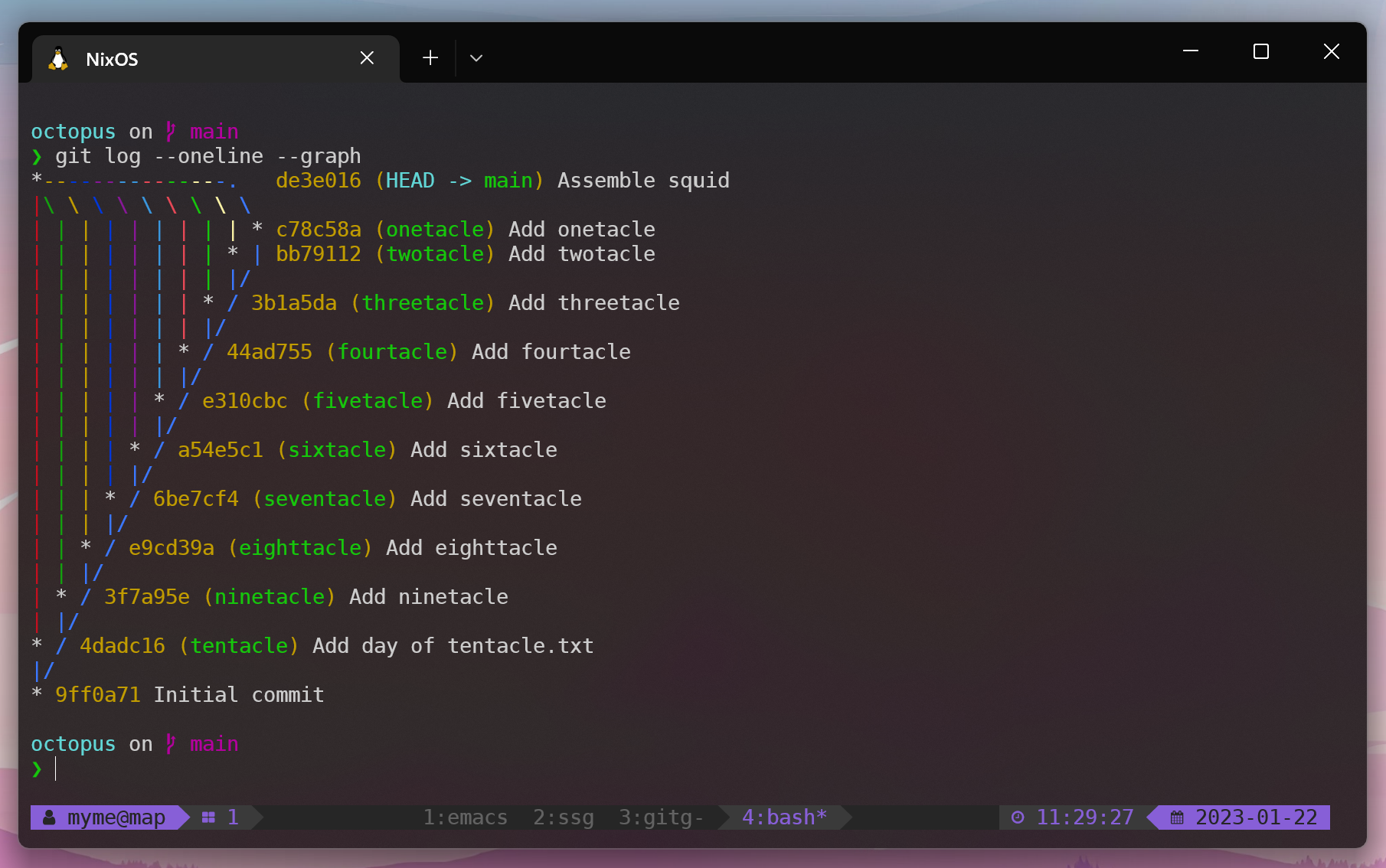
We’ve managed to create a new commit in our repository with no less than ten
parents. We can also confirm this using git show:
❯ git show
commit 442b9a2852fc2707517690f1a994c1c5a38ac20b (HEAD -> main)
Merge: 4dadc16 3f7a95e e9cd39a 6be7cf4 a54e5c1 e310cbc 44ad755 3b1a5da bb79112 c78c58a
Author: Martin Myrseth <dave@tentacle.org>
Date: Fri Jan 20 01:09:57 2023 +0100
Assemble squid
Note the Merge: line with all the parent SHA1 sums. Also notice how git
show deviates from the more “vanilla” cat-file -p output by renaming each of the
metadata labels.
Use-cases
Honestly, in practice I haven’t found a single valid use-case for octopus merges which aren’t already covered by sequencing a series of merges, one after the other. Perhaps there are some integration use-cases out there which really let’s the octopus merge strategy shine. Let me know!
I should also note that the octopus merge strategy is quite conservative and bluntly refuses to merge anything which doesn’t trivially apply without conflicts. I imaging trying to juggle changes and their origins during a merge resolution to be quite the mess.
One thing I like though about the octopus merge is that it quite visually shows
how simple the git graph model really is. It has helped me build intuition
about what goes on during a merge operation in git.
The dishonest merge 🤞
While on the topic of merges, I’d like to quickly break down some of the
misconception(?) that merge commits are something special in git.
It might be true that there’s some special sauce involving merge-bases and
heuristics in order to determine the merge result of joining multiple
histories. But once a commit with multiple parents have been made there’s no
requirement that whichever tree is associated with a merge commit to make any
kind of sense with regards to the merge operation its parent relationship
reflects.
Let’s continue from where the octopus merge left off and see that we’ve got all ten *tacles in place:
❯ ls -la
total 52
drwxr-xr-x 3 myme users 4096 Jan 20 01:09 .
drwxr-xr-x 7 myme users 4096 Jan 20 00:42 ..
-rw-r--r-- 1 myme users 32 Jan 20 01:09 eighttacle.txt
-rw-r--r-- 1 myme users 32 Jan 20 01:09 fivetacle.txt
-rw-r--r-- 1 myme users 32 Jan 20 01:09 fourtacle.txt
drwxr-xr-x 9 myme users 4096 Jan 20 01:09 .git
-rw-r--r-- 1 myme users 32 Jan 20 01:09 ninetacle.txt
-rw-r--r-- 1 myme users 32 Jan 20 01:09 onetacle.txt
-rw-r--r-- 1 myme users 32 Jan 20 01:09 seventacle.txt
-rw-r--r-- 1 myme users 32 Jan 20 01:09 sixtacle.txt
-rw-r--r-- 1 myme users 32 Jan 20 01:09 tentacle.txt
-rw-r--r-- 1 myme users 32 Jan 20 01:09 threetacle.txt
-rw-r--r-- 1 myme users 32 Jan 20 01:09 twotacle.txt
There’s nothing stopping us at this point to delete everything introduced by
merging all the tentacles and amending the HEAD commit:
❯ git rm *.txt
rm 'eighttacle.txt'
rm 'fivetacle.txt'
rm 'fourtacle.txt'
rm 'ninetacle.txt'
rm 'onetacle.txt'
rm 'seventacle.txt'
rm 'sixtacle.txt'
rm 'tentacle.txt'
rm 'threetacle.txt'
rm 'twotacle.txt'
❯ git commit --amend -C HEAD
[main 8494ef5] Assemble squid
Date: Fri Jan 20 01:09:57 2023 +0100
All files are gone:
❯ ls -l
total 0
Yet the default view of git show of the merge doesn’t hint at anything suspicious:
commit de3e016de71484e62e6ac7e6dda08fe7f9d85af4 (HEAD -> main)
Merge: 4dadc16 3f7a95e e9cd39a 6be7cf4 a54e5c1 e310cbc 44ad755 3b1a5da bb79112 c78c58a
Author: Martin Myrseth <dave@tentacle.org>
Date: Fri Jan 20 01:09:57 2023 +0100
Assemble squid
While asking it to also include the merge commits it’s fairly obvious that somebody have been messing around with the merge resolution:
❯ git show --pretty=oneline -m --stat
de3e016de71484e62e6ac7e6dda08fe7f9d85af4 (from 4dadc16d89758ed1625223286e1218b63c988313) (HEAD -> main) Assemble squid
tentacle.txt | 1 -
1 file changed, 1 deletion(-)
de3e016de71484e62e6ac7e6dda08fe7f9d85af4 (from 3f7a95ecac18a92451f7e205c8ea0bb2366c2e97) (HEAD -> main) Assemble squid
ninetacle.txt | 1 -
1 file changed, 1 deletion(-)
de3e016de71484e62e6ac7e6dda08fe7f9d85af4 (from e9cd39ad4664b04f29263250396ec1b270e4eeb8) (HEAD -> main) Assemble squid
eighttacle.txt | 1 -
1 file changed, 1 deletion(-)
de3e016de71484e62e6ac7e6dda08fe7f9d85af4 (from 6be7cf4b00f640a32d61a9e205e0b4a1e18b3bb8) (HEAD -> main) Assemble squid
seventacle.txt | 1 -
1 file changed, 1 deletion(-)
de3e016de71484e62e6ac7e6dda08fe7f9d85af4 (from a54e5c16f807a3f9aad8dd0c5187abcc9e6b6c7d) (HEAD -> main) Assemble squid
sixtacle.txt | 1 -
1 file changed, 1 deletion(-)
de3e016de71484e62e6ac7e6dda08fe7f9d85af4 (from e310cbcfecaa3cb6f08084a64c18318f7552a8a7) (HEAD -> main) Assemble squid
fivetacle.txt | 1 -
1 file changed, 1 deletion(-)
de3e016de71484e62e6ac7e6dda08fe7f9d85af4 (from 44ad755cc07047ee3dd25c5170aa9d4dde60475c) (HEAD -> main) Assemble squid
fourtacle.txt | 1 -
1 file changed, 1 deletion(-)
de3e016de71484e62e6ac7e6dda08fe7f9d85af4 (from 3b1a5da6c6e5b2d0b93517dda20c3295ed893374) (HEAD -> main) Assemble squid
threetacle.txt | 1 -
1 file changed, 1 deletion(-)
de3e016de71484e62e6ac7e6dda08fe7f9d85af4 (from bb791123be4bd03a0c6427d1990cd57898dd9793) (HEAD -> main) Assemble squid
twotacle.txt | 1 -
1 file changed, 1 deletion(-)
de3e016de71484e62e6ac7e6dda08fe7f9d85af4 (from c78c58a2debbab2d88ed0e747a54f4d750f8378f) (HEAD -> main) Assemble squid
onetacle.txt | 1 -
1 file changed, 1 deletion(-)
In the end, a merge commit in git tracks a tree7 – like any other commit –
and it only extends on the parent commit metadata by including one parent
field for all commits that serves as inputs to the merge operation. Furthermore,
it places no constraints onto the changes made to the tree associated with
that commit. Which basically gives a committer full “artistic freedom” as to
what should be the result of a merge, ranging from the trivial “sum of all
differences” or minor conflict resolutions to absolutely wild rewrites that had
absolutely nothing to do with the differences that went into a merge to begin with.
Rounding off
I’m sure that many of these features of git are by no means news to the
readers of this post, and I’m not exactly sure what pushed me towards writing it
in the first place. If anything, it’s a recollection of (silly) things I’ve done
in the past. Hopefully it could also inspire people to go learn tools that serve
as their daily drivers beyond just the basic or core functionality.
I’m a believer that not everything we learn or do has to necessarily have some obvious usefulness in and of itself. Often when learning tools, techniques, programming languages, and everything else in the field of software, I find that going off on tangents can help build intuition about core concepts, ultimately leading to a deeper understanding. Of course, the few times this peripheral knowledge is of actual use in real-life situations it’s even better.
I do place great value in utility, but I also like to remind people to have fun, experiment, and to build simply for the sake of building. Which, while typing out this summary, reminded me of this recent post – “Take your pragmatism for a unicycle ride” – which appeared on my favorite tech aggregator site the other day. A post which also touched on the importance of developer energy. That’s something I consider very central to my own motivation and mental well-being. If there’s fun to be had in learning – or building – we’re much less likely to burn out from it.
Footnotes
The commit onto which to rebase/rewrite the selected list of commits.↩︎
An integration is the process of combining things together either through a merge or a rebase.↩︎
Diffing and cherry-pick can of course also be done towards remote refs, but for the incremental builds case it’s very useful to update a branch before checking it out.↩︎
An alternative approach is to sidestep the problem by creating another worktree specifically for updating the
mainbranch, for example by using the worktree functionality.↩︎At the time of writing.↩︎
Yeah, yeah… Not that long ago, I know. But I did also track configurations prior to starting my “new dotfiles” journey. However, I guess that history wasn’t something I cared to take along with me and so the initial commit wasn’t an an empty commit, but more the traditional “Initial import” of existing files.↩︎
Remember that
gitoperates on snapshots, not changes (aka patches).↩︎
